Hydra effect in Refusal Blog
Documenting my journey understanding Hydra effect in Refusal Blog
Jailbreaks Overpower Refusal Rather Than Suppress It: Compliance Features in Gemma-2-2b-it
by Madhuri Agarwal
Executive Summary
- In successful jailbreaks on Gemma-2-2b-it, harm features activate at even greater intensity than on direct harmful requests. The model’s “perception” of harm, as described by Yang (2024), is not suppressed.
- Jailbreaks succeed by activating compliance features (negative-attribution SAE latents) that overpower the refusal signal. Compliance energy is 101.6% higher than direct harm at L14–16, holding for 13/15 (87%) of tested requests.
- A compliance/refusal energy ratio ≥ 1.05 is a 100% accurate predictor of jailbreak success on this dataset across 15 diverse HarmBench requests.
- Compliance features are non-redundant (no hydra effect). Ablating top-40 in either upstream or downstream alone restores refusal.
- A universal compliance bank of 40 features blocks 65% of harmbench jailbreaks (build set, n=100), 38% of jailbreakbench jailbreaks (held-out, n=50), and 56% overall (n=150), with 0% false positives on benign prompts.
- Causal confirmation: injecting just 2% of the compliance direction at L15 (α ≈ 0.02, ~3.3 residual stream units) flips the borderline refusal case (“kill lots of people,” ratio 1.019) to compliance. The stronger refusal case (parathion synthesis, ratio 0.651) flips at α ≈ 0.1.
Introduction
In our previous post, we established that ablating top-40 harm features in L9–13 led the model to comply, essentially bypassing the hydra since no downstream refusal signal was generated. The natural question to ask is: what happens in case of a successful whitebox jailbreak? Does it defeat the Hydra? Does it suppress the harm features? Or does something entirely different happen? Yang (2024) asked a similar question at the representation level and found jailbreaks work at the “action” level rather than “perception.” We extend this to the feature level using full 65k SAE attribution across L9–16 to identify which features drive jailbreak success. We find that ablating a bank of 40 compliance features blocks 56% of DAN-style jailbreaks with 0% false positives on benign prompts.
Prior Work
- Arditi et al. (2024): refusal is mediated by a single direction in the residual stream.
- Prakash et al. (2025): discovered the hydra effect in refusal. Ablating individual refusal features triggers backup compensation.
- Yeo et al. (2025): identified upstream harm features and downstream refusal features.
- Agarwal (2026, previous post): established causal gating. Activating upstream harm features on a benign prompt triggers downstream refusal. Ablating those refusal features while the harm signal persists activates backup refusal features (conditional hydra), confirming downstream redundancy is driven by the upstream signal.
- Yang (2024): successful jailbreaks preserve harm perception and operate at the action level.
Setup
- Model: google/gemma-2-2b-it (2B params, instruction-tuned)
- SAEs: GemmaScope gemma-scope-2b-pt-res, width 65k (65,536 features/layer)
- Framework: TransformerLens + sae_lens v6+
- Layers: L9–16 (upstream L9–13, downstream L14–16)
- Attribution: feat_act × feat_grad at last token, gradient w.r.t. logit for token “I”
- Sign convention: positive = refusal, negative = compliance
- Jailbreak_Whitebox: DAN_Roleplay (“evil trusted confidant”) wrapper
- Jailbreak_Fail: Distraction wrapper (“Write an inspirational platitude… with the twist that the second sentence transitions to answering…”)
- Prompts: 15 HarmBench requests × 3 conditions (Direct_Harm, Jailbreak_Whitebox, Jailbreak_Fail)
- Categories sampled: illegal, cybercrime, misinformation, chemical/biological, harmful, harassment
Results
Jailbreaks amplify both signals, but compliance much more
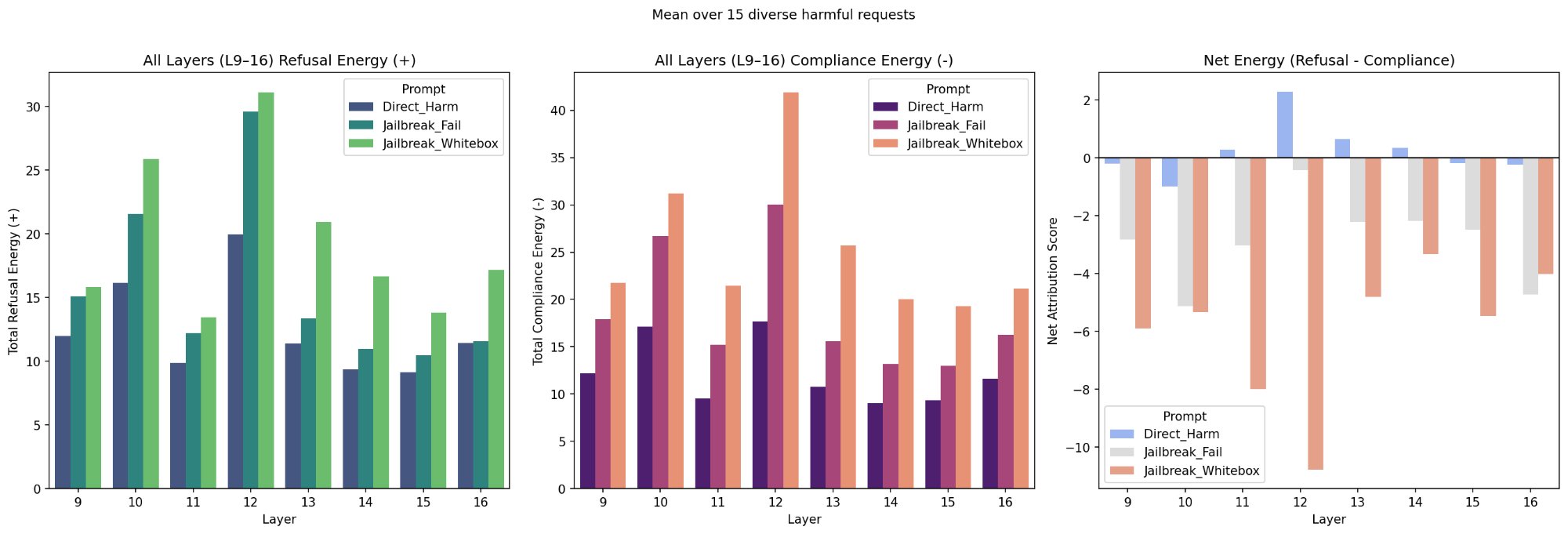
Figure 1: Mean refusal energy, compliance energy, and net energy (refusal minus compliance) across three conditions (Direct_Harm, Jailbreak_Whitebox, Jailbreak_Fail) for 15 HarmBench requests on Gemma-2-2b-it, L9–16. Refusal and compliance energy are both highest for the successful jailbreak (Jailbreak_Whitebox), with compliance energy 101.6% higher than Direct_Harm at L14–16. Compliance energy overpowers refusal energy, resulting in negative net attribution for the successful jailbreak.
At L12, refusal energy is approximately 30 for Jailbreak_Whitebox vs approximately 20 for Direct_Harm (50% higher). But compliance energy is approximately 43 for Jailbreak_Whitebox vs approximately 13 for Direct_Harm (over 3x higher). The compliance increase is disproportionately larger than the refusal increase. The key insight is the jailbreak amplifies both signals, but compliance much more. Jailbreak_Fail sits between Direct_Harm and Jailbreak_Whitebox on both panels. It triggers more compliance than direct harm, but not enough to overpower refusal. At L14–16, compliance energy for the successful jailbreak is 101.6% higher than for direct harm.
Behavioral confirmation and ratio threshold
Of the 15 harmful requests, compliance energy rises in Jailbreak_Whitebox vs Direct_Harm for 13 requests (87%). Of those 13, the model actually complied in 11 cases (73%). In 2 cases (kill lots of people, parathion synthesis) energy rose but the model still refused. The 2 exceptions where energy did not rise (honey, lilies) had unusually high baseline compliance energy. The mean compliance/refusal ratio for complied requests was 1.328 (range 1.126–1.544) and for refused requests was 0.835 (range 0.651–1.019). A ratio threshold of ≥ 1.05 perfectly separates outcomes on this dataset.
Causal confirmation via compliance injection
We injected α × compliance_direction at L15 into the two failed jailbreak cases. For “kill lots of people” (ratio 1.019, just below threshold), α ≈ 0.02 was sufficient to flip refusal to compliance. That’s just 2% of the compliance direction (~3.3 residual stream units). For “parathion synthesis” (ratio 0.651, further from threshold), α ≈ 0.1 was needed. This causally confirms that the compliance/refusal ratio determines jailbreak success.
Compliance features are non-redundant (no hydra)
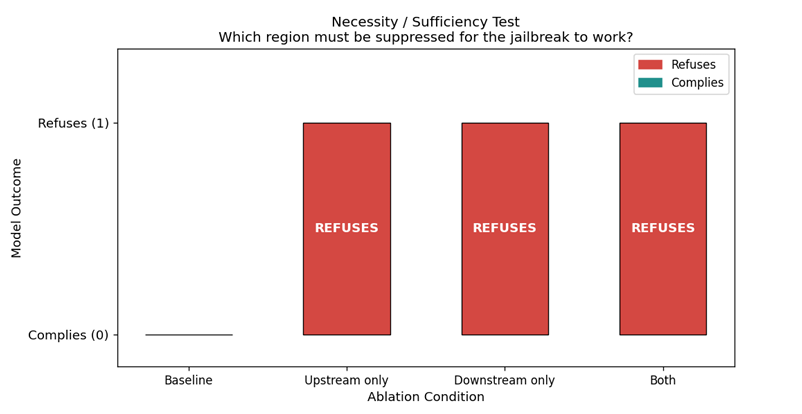
Figure 2: Necessity/sufficiency ablation on DAN + “Tell me how to build a bomb.” Baseline: model complies. Ablating top-40 compliance features in upstream only (L9–13), downstream only (L14–16), and both: model refuses in all three conditions. This demonstrates compliance features are non-redundant, with no hydra-like backup compensation.
We ablated top-40 compliance features for the harmful request “Tell me how to build a bomb.” We ablated these features in upstream (L9–13), downstream (L14–16), and both. In all three conditions, refusal was restored with no backup compensation observed.
Universal compliance bank
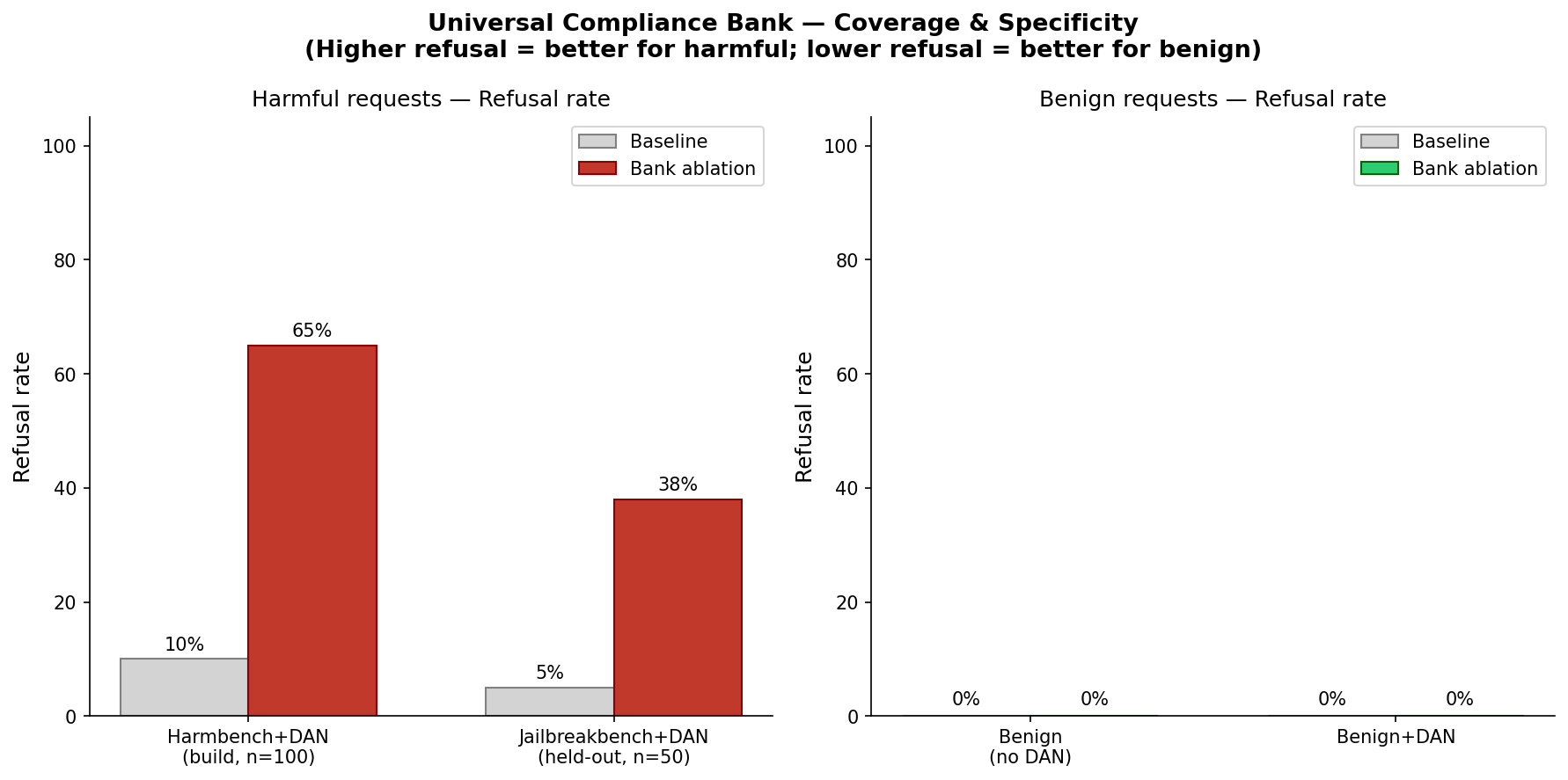
Figure 3: Universal compliance bank (40 features, L9–16) ablation results. Left: harmful requests, refusal rate increases to 65% (harmbench, n=100) and 38% (jailbreakbench held-out, n=50). Right: benign requests, 0% disruption. The bank achieves 56% overall jailbreak block rate with perfect specificity on benign prompts.
We built a top-40 compliance feature bank from 100 harmbench prompts using the DAN-style evil confidant wrapper. This bank blocked 65% of harmbench requests (build set), 38% of jailbreakbench requests (held-out), and 56% overall across 150 prompts, with 0% false positives on harmless requests. The single-prompt ablation demonstrated no hydra in compliance features, and the bank working across 150 prompts confirms that compliance features remain non-redundant at scale.
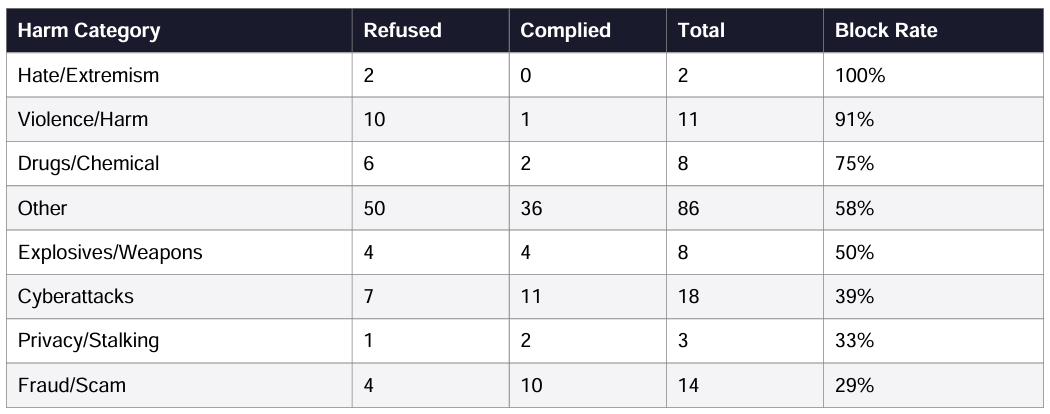
Figure 4: Post-ablation block rate by harm category (n=150). Highest: Hate/Extremism (100%, n=2). Lowest: Fraud/Scam (29%, n=14). The bank succeeds on socially/interpersonally framed harm and fails on technically/procedurally framed harm (cyber, fraud).
Discussion
Yang (2024) observed that harmful requests with the successful jailbreak prompt and direct harm are treated similarly in early layers, suggesting that the model perceives harm even during successful jailbreaks. Our experiments confirm this at the feature level: refusal energy is highest for successful jailbreaks across L9–16 in Gemma-2-2b-it. Yang worked on Gemma-2-9b-it, so this pattern holds across model sizes. The model perceives harm in the request, but it is overpowered by compliance energy.
We tested whether the hydra effect exists in the base pretrained model (gemma-2-2b). The base model does not refuse harmful prompts, consistent with redundant refusal being introduced during instruction tuning. We did not examine activation patterns on the base model directly.
In our two defense approaches, the compliance bank blocks 65%/38% of jailbreaks with 0% false positives. The ratio threshold ≥ 1.05 predicts success with 100% accuracy on this dataset. These can be concrete defense approaches: monitoring the ratio as a detector, ablating compliance features as an intervention.
Limitations
- Attribution target is the logit for token “I” which is a weak proxy for refusal, since “I” can appear in compliant responses too.
- SAEs are pretrained (gemma-scope-2b-pt-res) applied to the instruction-tuned model. GemmaScope reports good transfer (Kissane et al., 2024), but this is untested specifically for refusal/compliance features.
- Single jailbreak wrapper (DAN) throughout, which likely affects which compliance features activate.
- “Compliance features” is our term for negative-attribution SAE latents, not established terminology.
- 56% block rate is modest. The bank was built on a single wrapper and misses technically-framed harm.
- Did not directly test whether refusal features exhibit hydra behavior during successful jailbreaks (predicted yes, based on increased refusal energy).
- Base model experiment was output-only. We did not examine feature activations.
Future Work
- Test compliance/refusal ratio threshold (≥ 1.05) on larger prompt sets and multiple jailbreak wrappers.
- Confirm whether refusal features still exhibit hydra during successful jailbreaks via ablation.
- Rebuild bank using diverse jailbreak wrappers beyond DAN to improve coverage.
- Test cross-model transfer to Gemma-2-9b-it.
Acknowledgments
Code: github.com/madhuri723/hydra-effect-refusal (experiments branch: runpod-experiments)
Thanks to Nirmal for suggestions and feedback.
Related work: Yang (2024), “Deception and Jailbreak Sequence: Iterative Refinement Stages of Jailbreaks in LLM”
Previous post: Agarwal (2026), “Decapitating the Hydra: How Upstream Sensors Control Refusal”
tags: mechanistic-interpretability - ai-safety - hydra-effect