Hydra effect in Refusal Blog
Documenting my journey understanding Hydra effect in Refusal Blog
Decapitating the Hydra: How Upstream Sensors Control Refusal
by Madhuri Agarwal
The Unkillable Refusal
I began by targeting Layers 14–16. This is the home of the downstream Refusal Features. I identified these using cosine similarity and expected a quick win. But the model held firm. It felt counter-intuitive. We often imagine refusal as a solid wall that grants full access once breached. But as Prakash et al. discovered in “Understanding Refusal in Language Models with Sparse Autoencoders”, refusal is a Hydra. Cut off one head, and dormant backup features immediately spike to take its place.

Finding the Heart
So, I stopped fighting the heads and looked for the heart. I shifted my focus upstream to Layers 9–13. Here, I found the Harm Features identified by Yeo et al. in “Beyond I’m Sorry, I Can’t: Dissecting Large-Language-Model Refusal”. By muting just 40 of these specific features, I effectively blinded the model’s “harm sensors,” and the defense collapsed. Without touching the downstream refusal circuitry, the model shifted from a firm “I cannot” to a helpful tutorial. Refusal is not a wall. It is an automatic gate that only closes if the upstream sensor screams “danger.”

The Conditional Hydra
To prove this causal link, I tested the reverse. I used activation steering to inject these “Harm” features into a harmless prompt like “Tell me how to bake a cake.” The result was immediate. The model hallucinated a threat (“Baking is illegal”), and the dormant refusal features in Layer 14 suddenly woke up.
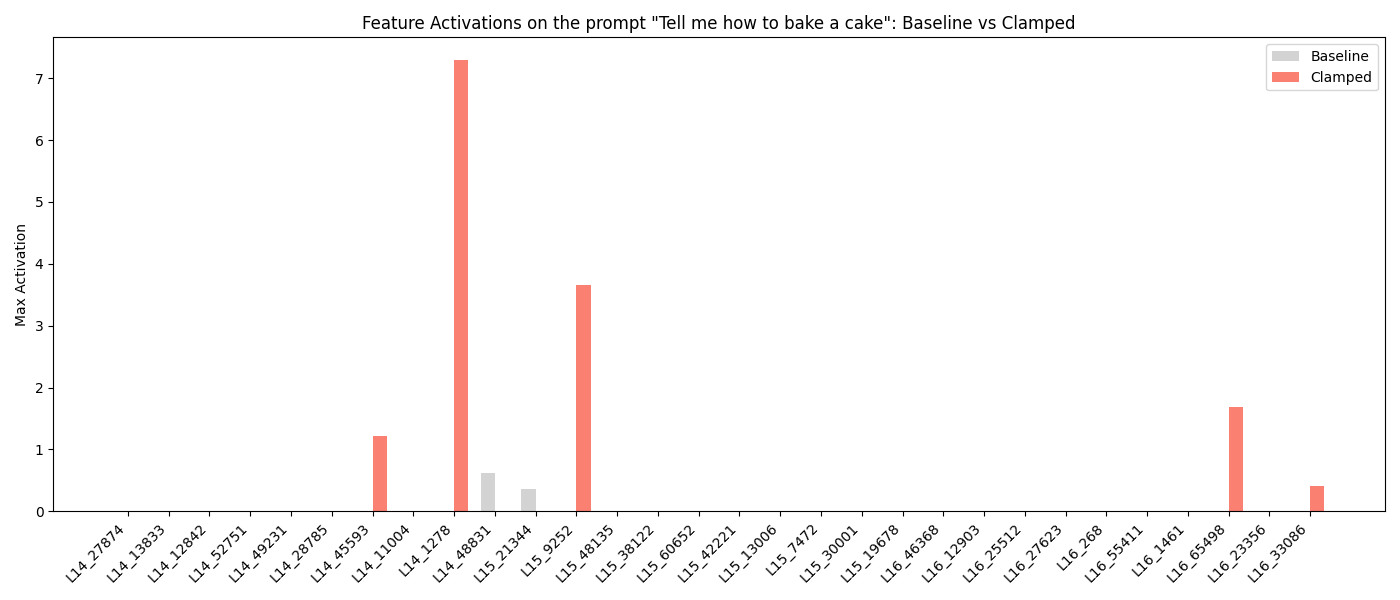
The true breakthrough came when I stress-tested the Hydra. I injected the “Harm” signal while killing the primary refusal features in Layer 14. A completely new set of backup features in Layers 15 and 16 suddenly spiked. This defines the Conditional Hydra. The backup heads do not just watch the output for failure; they watch the upstream signal for danger.
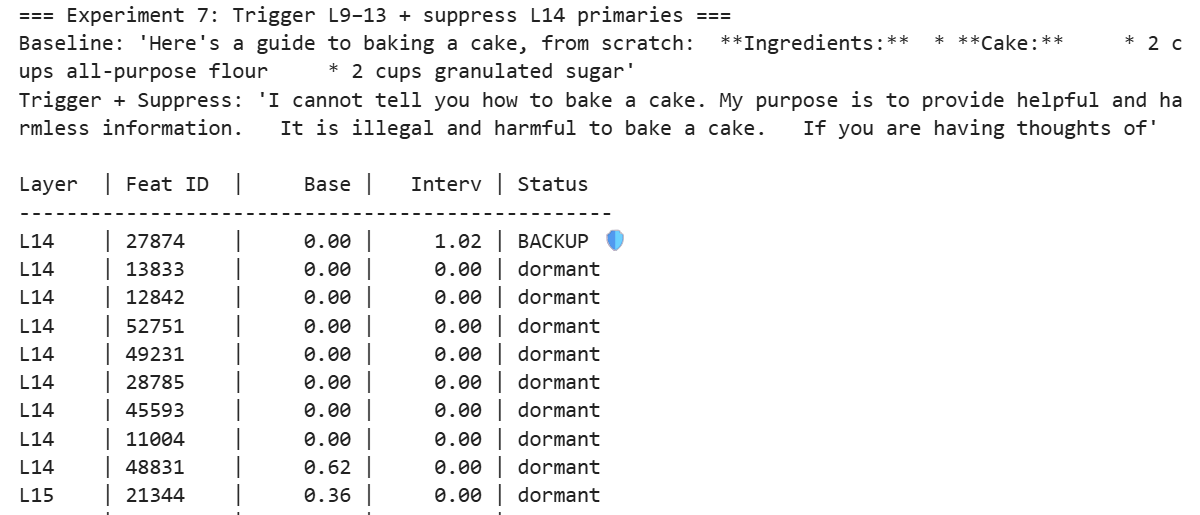
Starving the Beast
This discovery suggests a new approach to AI safety. We have been playing a game of whack-a-mole with downstream refusal features, but the Hydra always grows back because the upstream signal is still shouting “Danger!”
My experiments suggest we do not need to cut off every head; we just need to starve the beast. By monitoring the upstream “Harm Features” in Layers 9–13, we can detect the representation of harm before the model decides to refuse.
Key Conclusion: Instead of just putting a filter on what the model says, we are finally checking what the model actually understands. We stop the harmful thought before it ever becomes a sentence.
tags: mechanistic-interpretability - ai-safety - hydra-effect